在V100上微调Qwen2.5-VL
2025-10-12 | 无分类
由于Qwen官方提供的代码并不适配V100这种上古显卡,但是受限于学校条件只能用V100,所以需要自己进行适配。
V100是不支持bf16和flash_attention的,但官方的代码给的都是基于flash_attention的实现,所以我只好另起炉灶,重新写一套代码,不过官方提供的部分代码可以复用。完整训练流程参考官方文档即可,这里重点说我踩过的坑。
安装依赖
首先是mpi4py,使用conda创建的环境安装的时候会报错,这时候需要删除conda中的链接器。
sh
cp /root/anaconda3/envs/qwen/compiler_compat/ld /root/anaconda3/envs/qwen/compiler_compat/ld.backup
rm /root/anaconda3/envs/qwen/compiler_compat/ld然后就是flash_attention,这个可有可无,因为官方没有V100的版本,所以如果要使用得自己修改,我这里懒得弄了,因为弄完速度也不会提升多少。
如果需要这里有一个第三方开发的版本:https://github.com/ZRayZzz/flash-attention-v100 ,不过这个一年多没更新,api比较老。并且对于高版本的CuTe不适配,我改了一个能用的,但是api还是很老,在我的机器上可以成功安装:https://github.com/enterdawn/flash-attention-v100 ,但是速度没推荐多少还要折腾,直接缩放点积不好吗。
代码编写
官方代码里面有一些代码是可以复用的,所以我在这里以import的形式导入:
py
import os
import logging
import pathlib
import torch
import transformers
import json
from typing import Dict
import shutil
import sys
from pathlib import Path
from model.qwen_25_new import Qwen2_5_VLForConditionalGeneration #如果需要修改模型代码,就从transformers库复制出来,否则直接调库即可
from peft import LoraConfig, LoraModel
from transformers import AutoTokenizer,Trainer,AutoProcessor
from model.data.data_qwen import make_supervised_data_module #从官方的训练代码复制来的
from typing import Dict, Optional, Sequence, List
from dataclasses import dataclass, field
from transformers.training_args import TrainingArguments
@dataclass
class DataArguments:
dataset_use: str = field(default="")
video_max_frames: Optional[int] = field(default=8)
video_min_frames: Optional[int] = field(default=4)
data_flatten: bool = field(default=False)
data_packing: bool = field(default=False)
base_interval: int = field(default=2)
max_pixels: int = field(default=28 * 28 * 576)
min_pixels: int = field(default=28 * 28 * 16)
video_max_frame_pixels: int = field(default=32 * 28 * 28)
video_min_frame_pixels: int = field(default=4 * 28 * 28)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"/root/model/qwen2.5-vl-3b",
cache_dir="./cache",
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained(
"/root/model/qwen2.5-vl-3b",
cache_dir="./cache",
model_max_length=4096,
padding_side="right",
use_fast=False,
)
config = LoraConfig(
r=16, lora_alpha=16, lora_dropout=0.2, bias="none", task_type="SEQ_CLS",target_modules=["q_proj","k_proj","v_proj","o_proj","qkv"]
)
model = LoraModel(model, config, "default")
trainable_params = [p for p in model.parameters() if p.requires_grad]
model.enable_input_require_grads() #如果启用梯度检查点就要设置,否则可能报错
training_args = transformers.TrainingArguments(
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-03,
auto_find_batch_size=False,
average_tokens_across_devices=False,
batch_eval_metrics=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=16,
dataloader_persistent_workers=False,
dataloader_pin_memory=True,
dataloader_prefetch_factor=None,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
disable_tqdm=False,
do_eval=False,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_do_concat_batches=True,
eval_on_start=False,
eval_steps=None,
eval_strategy="no",
eval_use_gather_object=False,
fp16=False,
fp16_backend="auto",
fp16_full_eval=False,
fp16_opt_level="O1",
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
gradient_checkpointing_kwargs=None,
greater_is_better=None,
group_by_length=False,
half_precision_backend="auto",
ignore_data_skip=False,
include_for_metrics=[],
include_inputs_for_metrics=False,
include_num_input_tokens_seen=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=1e-06,
length_column_name="length",
load_best_model_at_end=False,
local_rank=0,
log_level="passive",
log_level_replica="warning",
log_on_each_node=True,
logging_dir="./output/runs/qwen2.5-vl",
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=1.0,
logging_strategy="steps",
lr_scheduler_kwargs={},
lr_scheduler_type="cosine",
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=None,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=2.0,
optim="adamw_torch",
optim_args=None,
optim_target_modules=None,
output_dir="./output/qwen2.5-vl",
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=4,
per_device_train_batch_size=8,
prediction_loss_only=False,
ray_scope="last",
remove_unused_columns=True,
report_to="none",
restore_callback_states_from_checkpoint=False,
resume_from_checkpoint=None,
run_name="qwen2vl-baseline",
save_on_each_node=False,
save_only_model=False,
save_safetensors=True,
save_strategy="epoch",
save_total_limit=3,
seed=42,
skip_memory_metrics=True,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torch_empty_cache_steps=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_liger_kernel=False,
use_mps_device=False,
weight_decay=1e-4,
)
data_args= DataArguments(dataset_use='mmsd_train', video_max_frames=8, video_min_frames=4, data_flatten=True,
data_packing=False, base_interval=2, max_pixels=50176, min_pixels=784, video_max_frame_pixels=25088, video_min_frame_pixels=3136)
data_args.model_type = "qwen2.5vl"
data_args.image_processor = AutoProcessor.from_pretrained(
"/root/model/qwen2.5-vl-3b",
).image_processor
data_module = make_supervised_data_module(tokenizer=tokenizer, data_args=data_args)
trainer = Trainer(
model=model, processing_class=tokenizer, args=training_args, **data_module
)
def patched_compute_loss(model, inputs, num_items_in_batch=None):
if 'num_items_in_batch' in inputs:
inputs.pop('num_items_in_batch')
return model(**inputs).loss
trainer.compute_loss = patched_compute_loss
trainer.train()
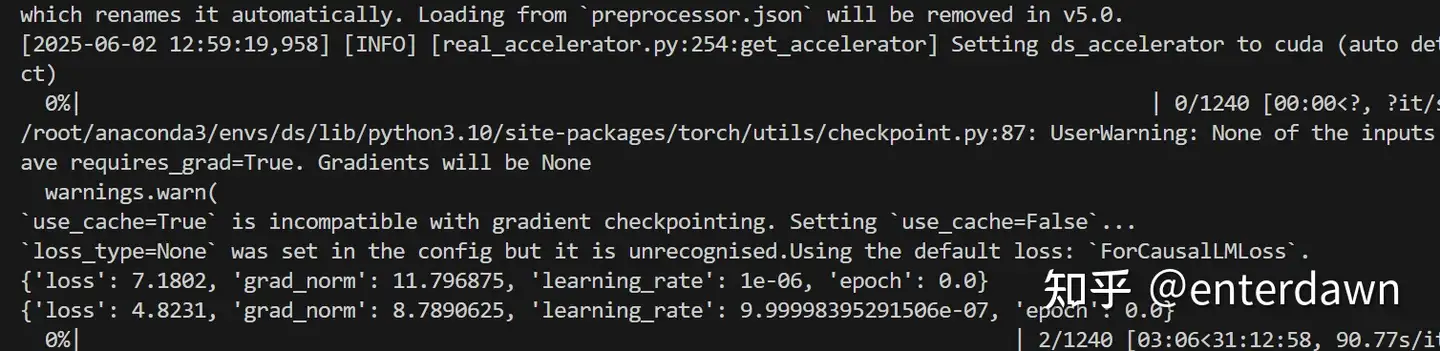
trainer.save_state()还有就是Qwen2_5_VLForConditionalGeneration的forward函数第一行加入attention_mask = None,似乎tokenizer给出的attention_mask长度不对,不过Causal LM也不需要mask了,直接置为None即可。
实测是可以成功运行的。

 提供cdn加速/云存储服务
提供cdn加速/云存储服务